Details
- About
- Technical
- Acquisition
- Additional
TopHat is a .NET middleware that sits in front of Anthropic and OpenAI and trims tool-result payloads before they cost you input tokens. The problem it solves is pretty common once you start building anything serious with LLMs: tool calls return big chunks of JSON, most of which the model never actually needs, and you end up paying full price for every byte of it on every turn.
Instead of just dropping data and hoping the model does not miss it, TopHat scores the items in a tool result for relevance, keeps the top N, summarizes what got cut, and quietly stands up a retrieval tool the model can use to ask for the dropped items if it actually needs them. This all happens transparently; from the application’s perspective, it is still just talking to Anthropic or OpenAI like normal.
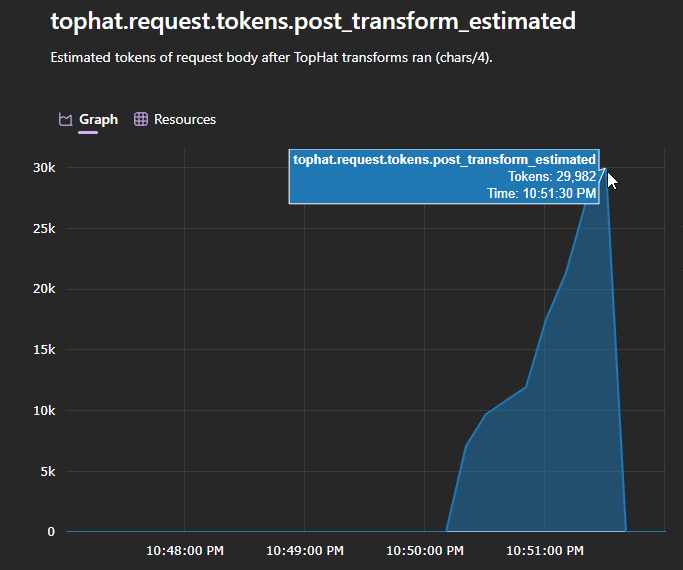
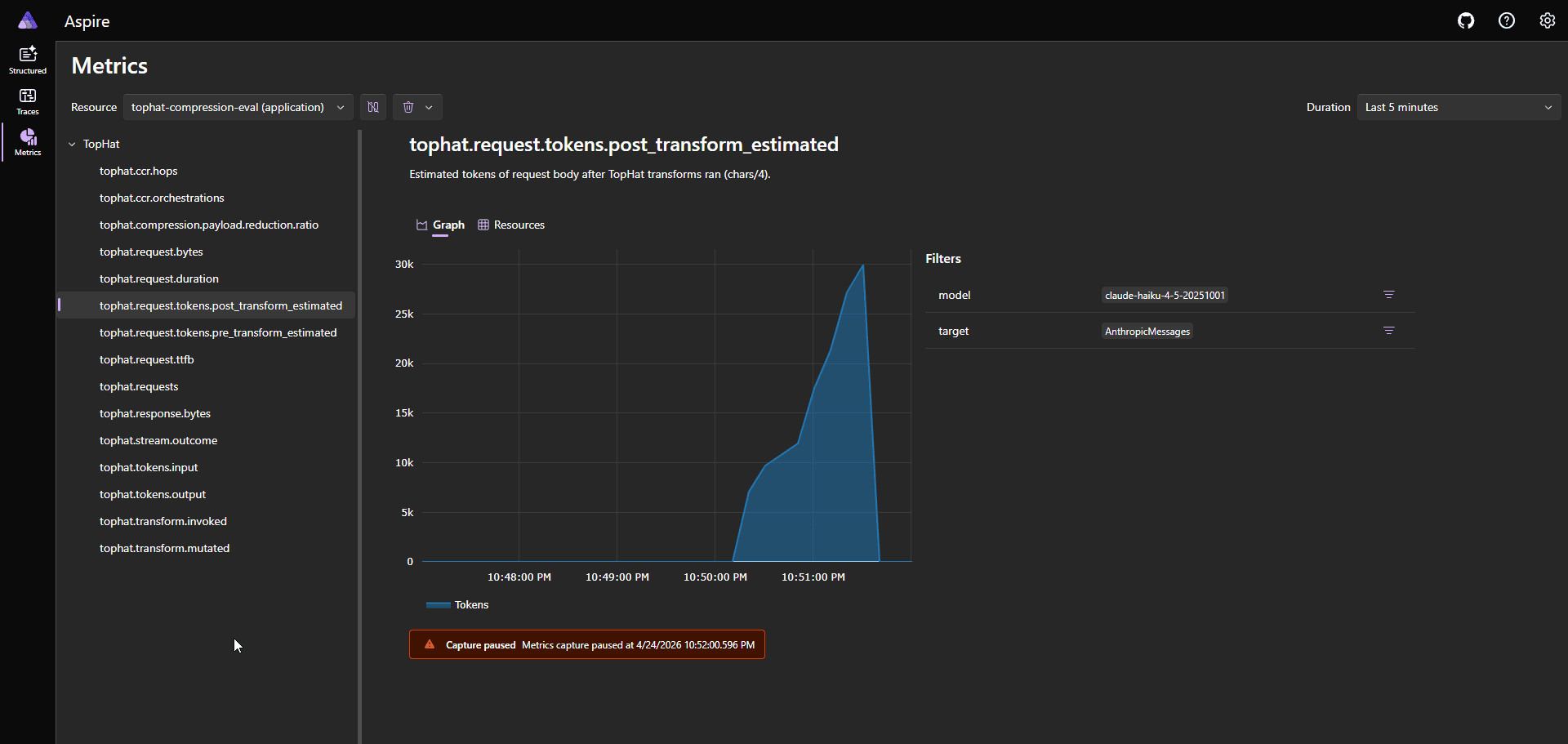
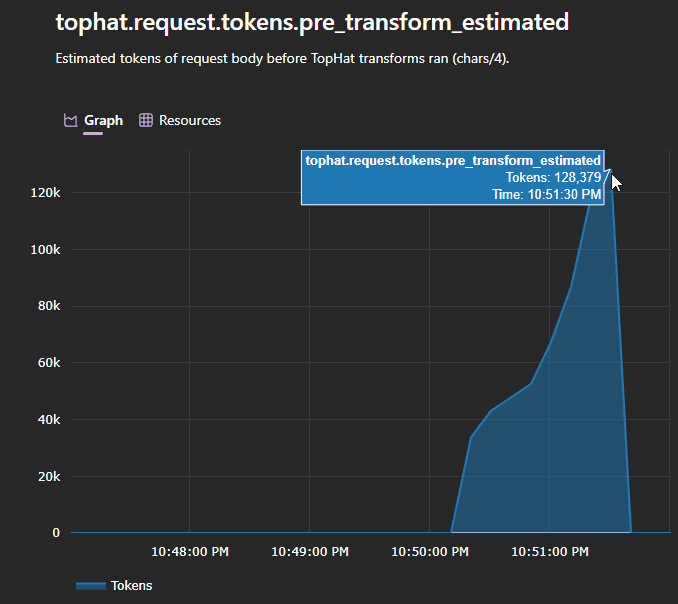
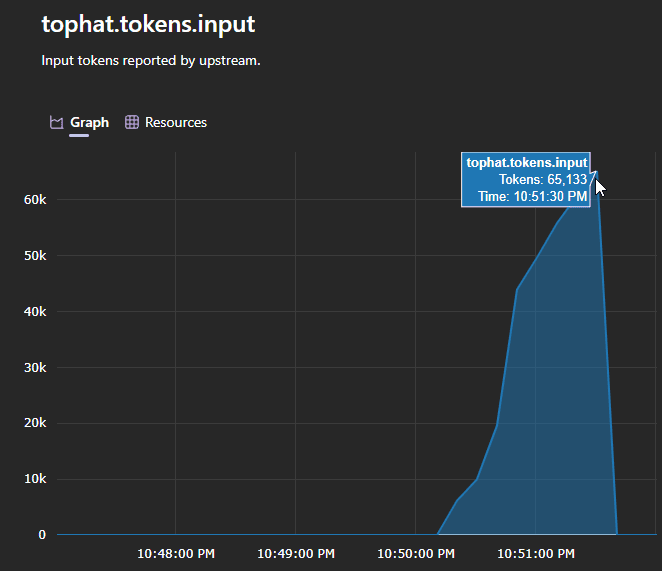
In an 8-fixture eval against live providers, it cut Anthropic costs by ~54% and OpenAI costs by 61% on the same workload. Savings vary a lot depending on what your tools return, but the pattern is consistent: the more your tools spit out partially relevant data, the more TopHat saves you.
TopHat hooks into the HttpClient pipeline as a DelegatingHandler, which means it slots in cleanly underneath the official Anthropic and OpenAI SDKs without any application changes beyond registering the handler. The interesting pieces are:
- Relevance scoring with fusion: Out of the box, there’s BM25 for keyword matching and an ONNX-based semantic scorer using MiniLM-L6-v2. Custom scorers can be plugged in, and scores from multiple scorers are fused automatically, so you don’t have to pick one approach.
- Compression Context Retrieval (CCR): Compressed payloads embed a retrieval key, and TopHat injects a synthetic
tophat_retrievetool into the request. When the model calls that tool, the handler intercepts the call in-band and returns the elided items without ever round-tripping back to the application. - Three-layer feedback system: Compression behavior can be controlled through static declarations, empirical learning over time, and runtime overrides, so you can tune how aggressive the compression gets per tool or per workload.
- OTel cost tracking: Pre and post compression token counts and savings are emitted as OpenTelemetry metrics, so the actual dollar impact is observable instead of guessed at.
- Provider coverage: Both Anthropic and OpenAI are supported, including OpenAI’s chat completions and responses endpoints.
Still deciding how I want this project to go. This may eventually become a NuGet package, but for now, it’s purely just a repository. The source is on GitHub for anyone who wants to read through the implementation or contribute.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}